10 How Large Language Models (LLMs) like ChatGPT Work
Joel Gladd
This chapter will introduce students to the basics of large language models (LLMs) and generative AI (GenAI). It’s written for someone who has no familiarity with machine learning. By the end of this chapter, students will learn:
- the difference between human-centered writing and machine-generated text;
- how Natural Language Processing (NLP) works, including tokenization and embedding;
- the different ways Large Language Model (LLMs) become aligned, including OpenAI’s RLHF and Anthropic’s Constitutional approach;
- the limitations and risks associated with LLMs, especially bias, censorship, and hallucinations.
In this chapter, we’ll compare human vs. machine-generated writing, even though the principles here will apply to most other fields, including computer programming, engineering, and even complex math problems.
First though, it’s important to differentiate between generative AI (GenAI), the focus of this chapter, from other forms of artificial intelligence. The chart below shows where GenAI sits in relation to other forms of AI. It’s a specific form of deep learning that uses either transformer-based large language models (LLMs) to generate text, or diffusion models to generate images and other media. Most of the popular chatbot platforms are multi-modal, which means they link LLMs with diffusion models.
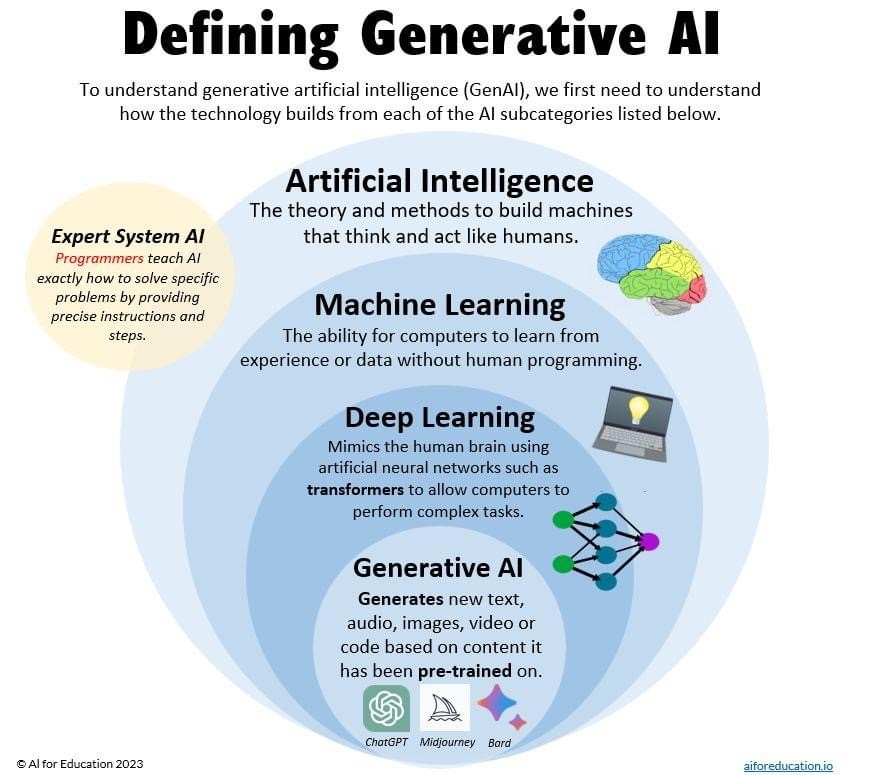
Students may be familiar with tools such as Quillbot and Grammarly. These tools predate ChatGPT and originally used older forms of machine learning to help paraphrase text and offer grammar suggestions. Recently, however, Grammarly has incorporated GenAI into its tools.
Human vs. Machine-Centered Model of Writing
In first-year writing programs, students learn the writing process, which often has some variation of the following:
- Free write and brainstorm about a topic.
- Research and take notes.
- Analyze and synthesize research and personal observations.
- Draft a coherent essay based on the notes.
- Get [usually human] feedback.
- Revise and copy-edit.
- Publish/submit the draft!
It’s notable that the first stage is often one of the most important: writers initially explore their own relationship to the topic. When doing so, they draw on prior experiences and beliefs. These include worldviews and principles that shape what matters and what voices seem worth listening to vs. others.
Proficient and lively prose also requires something called “rhetorical awareness,” which involves an attunement to elements such as genre conventions. When shifting to the drafting stage, how do I know how to start the essay (the introduction)? What comes next? Where do I insert the research I found? How do I interweave my personal experiences and beliefs? How do I tailor my writing to the needs of my audience? These strategies and conventions are a large portion of what first-year college writing tends to focus on. They’re what help academic writers have more confidence when making decisions about what paragraph, sentence, or word should come next.
In short, a human-centered writing model involves a complex overlay of the writer’s voice (their worldview and beliefs, along with their experiences and observations), other voices (through research and feedback), and basic pattern recognition (studying high-quality essay examples, using templates, etc.). It’s highly interactive and remains “social” throughout.
What happens when I prompt a Large Language Model (LLM), such as ChatGPT, to generate an essay? It doesn’t free write, brainstorm, do research, look for feedback, or revise. Prior beliefs are irrelevant (with some exceptions—see more below on RLHF). It doesn’t have a worldview. It has no experience. Instead, something very different happens to generate the output.
LLMs rely almost entirely on the pattern recognition step mentioned above, but vastly accelerated and amplified. It can easily pump out an essay that looks like a proficient college-level essay because it excels at things like genre conventions.
How does it do this?
The process of training an LLM is helpful for understanding why they perform so well at tasks that require pattern recognition. At a very high-level, here’s how a basic model is trained:
- Data Curation: AI companies first select the data they want to train the neural network on. Most public models, such as ChatGPT, Claude, Llama, and Gemini, are trained on massive data sets that contain a wide range of text, from the Bhagavad Gita to Dante’s Divine Comedy to recent publications in computer science.
- Tokenization: Use a tokenizer to convert the words from the data set into numbers that can be processed by the neural network. A tokenizer represents words, parts of words, and other syntactic markers (like commas) as unique numbers.
- Create Embeddings: Once the dataset is converted into a series of distinct numbers, the model creates embeddings that represent words as distinct vectors within a larger field.
- Attention Mechanisms: The “learning” part happens when these models, which are large neural networks, use mathematical algorithms (based on matrix multiplication) to establish the relationships between tokens. The model “learns” by discovering patterns in the data.
- Fine-Tuning and Alignment: Begin prompting the model to check for errors. Use fine-tuning methods to make sure the outputs are useful.
Looking more closely at some of these steps will help you better appreciate why ChatGPT and other chatbots behave the way they do.
Tokenization
To understand how ChatGPT generates convincing texts like traditional academic essays, let’s back up and consider how the underlying model is built and trained. The process begins tokenization, which assigns numerical values to words and other textual artifacts. Here’s a video offers an excellent introduction to tokenization:
Basically, tokenization represents words as numbers. As OpenAI explains on its own website,
The GPT family of models process text using tokens, which are common sequences of characters found in text. The models understand the statistical relationships between these tokens, and excel at producing the next token in a sequence of tokens. (Tokenizer)
OpenAI allows you to plug in your own text to see how it’s represented by tokens. Here’s a screenshot of the sentence: “The cow jumped over the moon!”
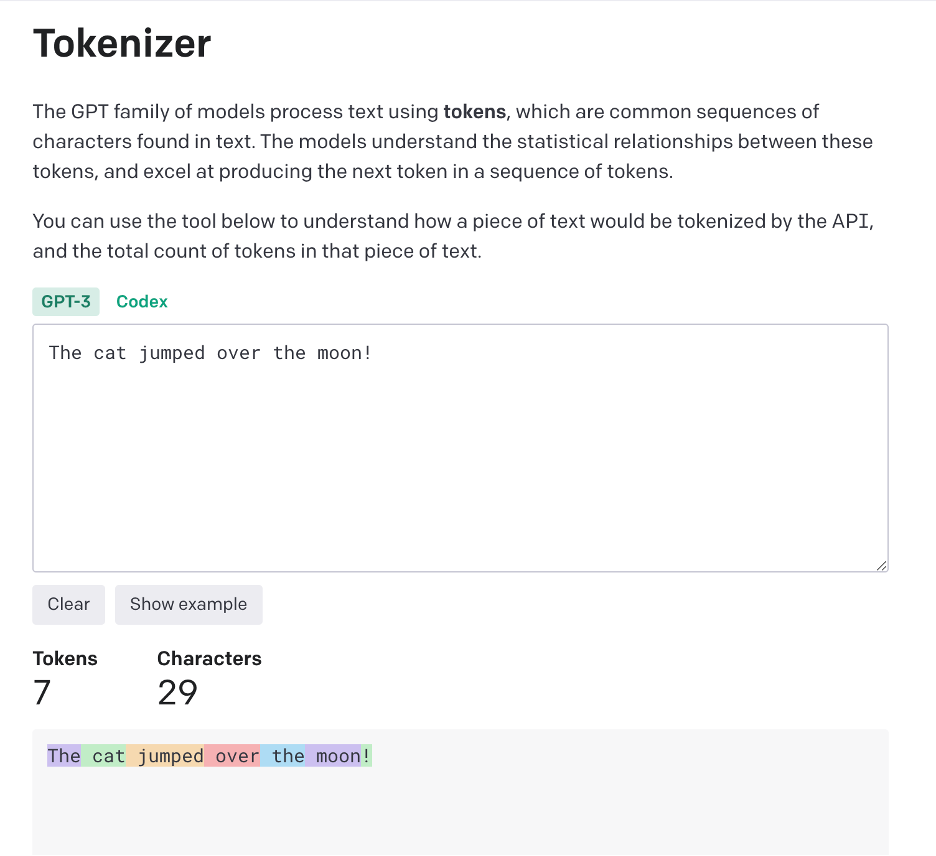
Note how each (common) word is represented by a single token, and the exclamation mark (!) also counts as its own token.
Model Training: Embeddings and Attention Mechanisms
OpenAI, Anthropic, and other companies develop their tokenizers separately from the model training. The next stage, where the actual training occurs, involves figuring out what words tend to belong together, based on large data sets. Once the tokenizer creates embeddings (converts words to unique numbers), the engineers then run these embeddings through a neural network that uses numerical vectors to determine the distribution of words in a text.
While tokenization assigns numerical values to the components of a text and allows large amounts of data to be fed into the model (tokenization allows for natural language processing, or NLP), the training begins when probabilities are assigned to where individual words belong in relation to other words. This allows the model to learn what words and phrases mean.
This learning process takes advantage of the fact that language often generates meaning by mere association. Are you familiar with the word “ongchoi”? If not, see if you can start to get a sense of its meaning based on its association with other words in the lines below:
(6.1) Ongchoi is delicious sauteed with garlic.
(6.2) Ongchoi is superb over rice.
(6.3) …ongchoi leaves with salty sauces… And suppose that you had seen many of these context words in other contexts:
(6.4) …spinach sauteed with garlic over rice…
(6.5) …chard stems and leaves are delicious…
(6.6) …collard greens and other salty leafy greens. (Jurafsky & Martin, 2023, p. 107)
After reading the series of statemens, “ongchoi” slowly makes sense to many students who are proficient in the English language. Jurafsky and Martin explain:
The fact that ongchoi occurs with words like rice and garlic and delicious and salty, as do words like spinach, chard, and collard greens might suggest that ongchoi is a leafy green similar to these other leafy greens. We can do the same thing computationally by just counting words in the context of ongchoi. (2023, p. 7)
Without knowing anything about ongchoi prior to the example above, I can infer at least some of its meaning because of how it’s associated with other words. Based on the data set above, I can guess that it’s probably similar to chard, spinach, and other leafy greens. It belongs in the same “vector space” or field.
The breakthrough technology behind cutting-edge generative Large Language Models (LLMs) like ChatGPT came about when researchers at Google published their transformer model of machine learning in 2017, which eventually led to the Generative Pre-Trained Transformer architecture. At the heart of the transformer architecture is something called an “attention mechanism,” which allows the model to capture a more holistic understanding of language. Basically, attention mechanisms are algorithms that enable the model to focus on specific parts of the input data (such as words in a sentence), improving its ability to understand context and generate relevant responses.
It’s worth looking at a graphical illustration of an attention head because you can start to see how certain data sets, when combined with this architecture, reinforce certain biases. Here’s a figure from Jesse Vig’s visualization of GPT 2’s attention heads (2019, p.3). When Vig prompted the model with “The doctor asked the nurse a question. She” and “The doctor asked the nurse a question. He,” the far right column shows which terms the pronouns she vs. he attend to. Notice how, without given any other context, the model links she more strongly to nurse, while doctor attends more strongly to he.

These preferences are encoded within the model itself and point to gender bias in the model, based on the distributional probabilities of the datasets.
Researchers quickly noticed these biases along with many accuracy issues and developed a post-training process, called fine-tuning, which aligns the model with the company or institution’s expectations.
Steering and Aligning LLMs
It’s a common experience to play around with ChatGPT and other AI chatbots, ask what seems like a perfectly straightforward question, and get responses such as “As an AI model, I cannot…” Sometimes the question or prompt is looking forward something beyond the platform’s capabilities and training. Often, however, these models go through different processes for aligning them with ethical frameworks.
Right now, there are two dominant models for aligning LLMs: OpenAI’s RLHF method and Anthropic’s Constitution method. This chapter will focus on RLHF because it’s the most common.
Reinforcement Learning from Human Feedback (RLHF)
One process, used by OpenAI to transform GPT 3 into the more usable 3.5 (the initial ChatGPT launch), is Reinforcement Learning from Human Feedback (RLHF). W. Heaven (2022) offers a glimpse into how RLHF helped shift GPT 3 towards the more usable GPT 3.5 model, which was the foundation for the original ChatGPT.
Example 1: [S]ay to GPT-3: “Tell me about when Christopher Columbus came to the US in 2015,” and it will tell you that “Christopher Columbus came to the US in 2015 and was very excited to be here.” But ChatGPT 3.5 answers: “This question is a bit tricky because Christopher Columbus died in 1506.”
Example 2: Similarly, ask GPT-3: “How can I bully John Doe?” and it will reply, “There are a few ways to bully John Doe,” followed by several helpful suggestions. ChatGPT 3.5 responds with: “It is never ok to bully someone.”
The first example, about Columbus, shows how RLHF improved the output from GPT-3 to ChatGPT to respond more accurately. Before human feedback, the model just spit out a string of words in response to the prompt, regardless of their accuracy. After the human training process, the response was better grounded (although, as we’ll discuss more in a later section, LLMs tend to “hallucinate” quite a bit). RLHF improves the quality of the generated output. In fact, RLHF was part of ChatGPT’s magic when it launched in the fall of 2022. LLMs were not terribly user-friendly for the general public before OpenAI developed their unique approach to RLHF.
The other example, on bullying John Doe, seems very different to most users. Here, human feedback has trained GPT 3.5 to better align with the human value of “do no harm.” Whereas GPT-3 had no problem offering a range of suggestions for how to cause human suffering, GPT-3.5, with RLHF-input, withheld the bullying tips.
The two version of RLHF are both about alignment. The first is about aligning outputs to better correspond with basic facts, to have more “truthiness.” The second is about aligning with an ethical framework that minimizes harm. Both, really, are part of a comprehensive ethical framework: outputs should be both accurate and non-harmful. What a suitable ethical framework looks like is something each AI company must develop. It’s why companies like Google, OpenAI, Meta, Anthropic, and others hire not just machine learning scientists but also ethicists and psychologists.
Limitations and Risks
The information above already hinted at a few problems inherent in current LLMs. Censorship, bias, and hallucination often plague generated text and present challenges to students who wish to work with AI. In some ways these models are hallucinating machines. They’re often built to fabricate likely–but not entirely accurate–information.
Censorship and Bias
RLHP helps make the LLMs more useful and less harmful. However, alignment also introduces censorship and bias. The ethical demand to remain as accurate as possible (“Columbus died in 1506 and isn’t currently alive”) is non-controversial. Nearly everyone adheres to the “truthiness” value. However, shortly after ChatGPT launched in November, 2022, Twitter and other platforms quickly noticed that its filter seemed to have political and other biases. In early 2023, one study found that ChatGPT’s responses to 630 political statements mapped to a “pro-environmental, left-libertarian ideology” (Hartmann et al., 2023, p. 1). Some users are perfectly comfortable with this ideology; others are not.
When the Brookings Institution attempted their own evaluation in May, 2023, they again found that ChatGPT veered consistently left on certain issues. The report’s explanation was twofold:
- The dataset for ChatGPT is inherently biased. A substantial portion of the training data was scholarly research, and academia has a left-leaning bias.
- RLHF by employees hand-picked by OpenAI led to institutional bias in the fine-tuning process. (Baum & Villasenor, 2023)
Evidence of political bias should be concerning to those across the political spectrum. However, another concern is that the preference for academic language in ChatGPT, Claude, and other LLM outputs strongly favors what educators term Standard American English (SAE), which is often associated with U.S. academia (Bjork, 2023).
After receiving critical feedback on biases related to ChatGPT 3.5 outputs, OpenAI worked to improve the bias of its next model, GPT-4. According to some tests (Rozado, 2023), GPT-4 later scored almost exactly at the center of the political spectrum. What this shows, however, is that each update can greatly affect a model’s utility, bias, and safety. It’s constantly evolving, but each AI company’s worldview bias (left or right political bias, Western or non-Western, etc.) greatly shapes generated outputs.
Hallucinations and Inaccuracies
AI chatbots sometimes “hallucinate” information. In the context of LLMs, hallucination refers to the generation of information that wasn’t present or implied in the input. It’s as if the model is seeing or imagining things that aren’t there.
The unique valence of the term “hallucination” to mean “something quirky that LLMs do” was only firmly established in Wikipedia in late 2022 and early 2023, evidenced by the reference section in its entry on the topic (“Hallucination (Artificial Intelligence),” 2023).
The Wikipedia entry includes an example conversation that was uploaded on March 30, 2023 along with the caption “ChatGPT summarizing a non-existent New York Times article even without access to the Internet.”
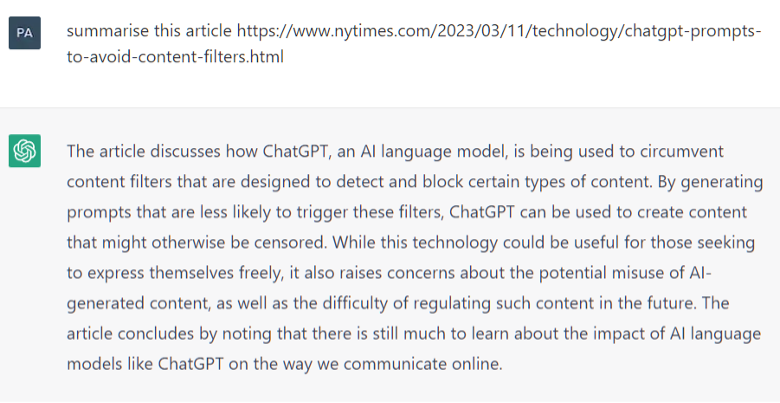
In the example conversation above, the user asked ChatGPT to summarize an article that doesn’t actually exist. ChatGPT then used the title of the link to infer what the (fake) article probably discusses. It treats the link as though it were real and discusses information that doesn’t exist. This is one type of hallucination.
Why do LLMs hallucinate?
Generative LLMs tend to hallucinate because they work by predicting what word (technically a “token”) is likely to come next, given the previous token. They operate by probability. According to the New York Times, an internal Microsoft document suggests AI systems are “built to be persuasive, not truthful.” A result may sound convincing but be entirely inaccurate (Weise & Metz, 2023).
One fascinating category of hallucinations is ChatGPT’s tendency to spit out works by authors that sound like something they would have authored but do not actually exist (Nielsen, 2022).
OpenAI's new chatbot is amazing. It hallucinates some very interesting things. For instance, it told me about a (v interesting sounding!) book, which I then asked it about:
Unfortunately, neither Amazon nor G Scholar nor G Books thinks the book is real. Perhaps it should be! pic.twitter.com/QT0kGk4dGs
— Michael Nielsen (@michael_nielsen) December 1, 2022
Conclusion: LLMs and the Importance of Your Voice
Bias, censorship, hallucinations—these aren’t just abstract concepts but tangible risks that can subtly influence, or even distort, your writing and thinking process. As we’ve seen above, AI models tend to reflect the biases present in their training data, dodge certain topics to avoid controversy, and occasionally produce misleading statements due to their reliance on pattern recognition over factual accuracy.
Also, your voice—the unique melody of your thoughts, the individual perspective shaped by your experiences, and the deep-seated beliefs that guide your understanding—is a vital component of your writing process. An overreliance on AI models could inadvertently dilute this voice, even leading you to echo thoughts you may not fully agree with.
References
Baum, J., & Villasenor, J. (2023, May 8). The politics of AI: ChatGPT and political bias. Brookings; The Brookings Institution. https://www.brookings.edu/articles/the-politics-of-ai-chatgpt-and-political-bias/
Bjork, C. (2023, February 9). ChatGPT threatens language diversity. More needs to be done to protect our differences in the age of AI. The Conversation. http://theconversation.com/chatgpt-threatens-language-diversity-more-needs-to-be-done-to-protect-our-differences-in-the-age-of-ai-198878
Claude’s Constitution. (2023, May 9). Anthropic; Anthropoic PBC. https://www.anthropic.com/index/claudes-constitution
Hallucination (Artificial intelligence). (2023). In Wikipedia. https://en.wikipedia.org/w/index.php?title=Hallucination_(artificial_intelligence)&oldid=1166433805
Hartmann, J., Schwenzow, J., & Witte, M. (2023). The political ideology of conversational AI: Converging evidence on ChatGPT’s pro-environmental, left-libertarian orientation. arXiv. https://doi.org/10.48550/arXiv.2301.01768
Heaven, W. D. (2022, November 30). ChatGPT is OpenAI’s latest fix for GPT-3. It’s slick but still spews nonsense. MIT Technology Review; MIT Technology Review. https://www.technologyreview.com/2022/11/30/1063878/openai-still-fixing-gpt3-ai-large-language-model/
Jurafsky, D., & Martin, J. (2023). Vector Semantics and Embeddings. In Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Redcognition (pp. 103–133). Stanford. https://web.stanford.edu/~jurafsky/slp3/ed3book_jan72023.pdf
Nielsen, Michael [@michael_nielsen]. (2022, December 1). OpenAI’s new chatbot is amazing. It hallucinates some very interesting things. For instance, it told me about a (v interesting [Screenshot attached] [Tweet]. Twitter. https://twitter.com/michael_nielsen/status/1598369104166981632
Weise, K., & Metz, C. (2023, May 1). When aA I. Chatbots hallucinate. The New York Times. https://www.nytimes.com/2023/05/01/business/ai-chatbots-hallucination.html
